Lancement officiel de DeepSeek-V4 : Contexte d'un million de tokens, architecture d'attention hybride et un nouveau SOTA pour les modèles ouverts

Aujourd'hui marque le lancement officiel de DeepSeek-V4. Avec le lancement officiel de DeepSeek-V4, l'équipe a maîtrisé le contexte d'un million de tokens. En introduisant une architecture d'attention hybride, cette mise à jour établit un nouveau SOTA pour les modèles ouverts.
Le lancement officiel de DeepSeek-V4 brise la barrière de l'efficacité. Voici comment son architecture d'attention hybride et le contexte d'un million de tokens redéfinissent le nouveau SOTA pour les modèles ouverts.
1. La Matrice de Modèles : Conçue pour un contexte d'un million de tokens
Le lancement officiel de DeepSeek-V4 inclut deux modèles MoE, supportant un contexte d'un million de tokens :
- DeepSeek-V4-Pro : Gère facilement un contexte d'un million de tokens.
- DeepSeek-V4-Flash : Rend le contexte d'un million de tokens très accessible.
2. Percée : L'architecture d'attention hybride
Pour une efficacité extrême sous un contexte d'un million de tokens, le lancement officiel de DeepSeek-V4 introduit son architecture d'attention hybride :
- Architecture d'attention hybride : Cette architecture d'attention hybride combine CSA et HCA.
3. Efficacité de l'architecture d'attention hybride
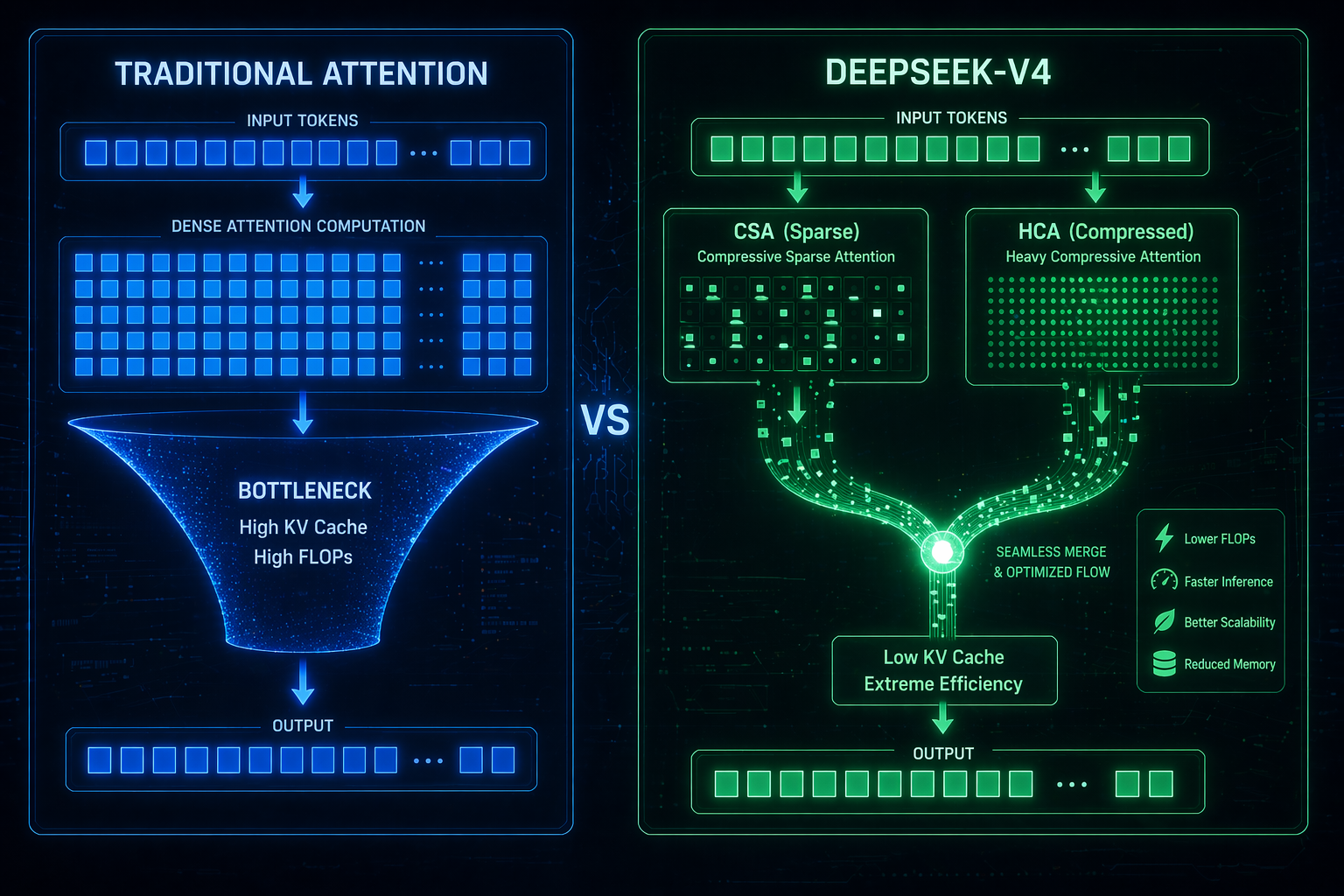
Traiter un contexte d'un million de tokens nécessite de la puissance, mais le lancement officiel de DeepSeek-V4 montre une optimisation incroyable :
- Propulsé par l'architecture d'attention hybride, le FLOPs est réduit à 27%.
- Sous le même contexte d'un million de tokens, le cache KV n'est que de 10%.
4. Benchmarks : Un nouveau SOTA pour les modèles ouverts
Le lancement officiel de DeepSeek-V4 a été pré-entraîné pour garantir ce nouveau SOTA pour les modèles ouverts.
- DeepSeek-V4-Pro-Max redéfinit le nouveau SOTA pour les modèles ouverts.
- En programmation, ce nouveau SOTA pour les modèles ouverts est 23ème sur Codeforces.
- Le lancement officiel de DeepSeek-V4 a obtenu 120/120 sur Putnam-2025.
5. Mises à niveau pour l'IA Agentique

Au-delà du contexte d'un million de tokens, le lancement officiel de DeepSeek-V4 consolide sa position en tant que nouveau SOTA pour les modèles ouverts.
Conclusion
Le lancement officiel de DeepSeek-V4 a transformé le contexte d'un million de tokens en réalité grâce à une architecture d'attention hybride. Nous assistons à un nouveau SOTA pour les modèles ouverts.