DeepSeek-V4 公式リリース:100万トークンコンテキスト、ハイブリッドアテンションアーキテクチャ、そしてオープンモデルの新しいSOTA

今日は待望の DeepSeek-V4 公式リリース の日です。DeepSeek-V4 公式リリース により、チームはAI機能の歴史的な飛躍を実現し、特に 100万トークンコンテキスト を完全に制御しました。革新的な ハイブリッドアテンションアーキテクチャ を導入することで、このアップデートは確固たる オープンモデルの新しいSOTA を確立します。
基盤システムの深い再構築を通じて、DeepSeek-V4 公式リリース は超長文処理の効率の壁を打ち破りました。ここでは、その ハイブリッドアテンションアーキテクチャ と 100万トークンコンテキスト がどのように オープンモデルの新しいSOTA を再定義するかを紹介します。
1. コアモデルマトリックス:100万トークンコンテキスト向け
DeepSeek-V4 公式リリース プレビューには、100万トークンコンテキスト をネイティブにサポートする2つの強力なMoEモデルが含まれています:
- DeepSeek-V4-Pro: 1.6Tパラメータを持ち、100万トークンコンテキスト を容易に処理します。
- DeepSeek-V4-Flash: 284Bパラメータを持ち、100万トークンコンテキスト へのアクセスを容易にします。
2. ブレイクスルー:ハイブリッドアテンションアーキテクチャ
100万トークンコンテキスト 下での極限の効率を達成するため、DeepSeek-V4 公式リリース は ハイブリッドアテンションアーキテクチャ を筆頭に3つの革新を導入しました:
- ハイブリッドアテンションアーキテクチャ: この ハイブリッドアテンションアーキテクチャ はCSAとHCAを組み合わせ、計算効率を大幅に向上させます。
- mHC: ハイブリッドアテンションアーキテクチャ と共に残差接続を強化します。
- Muonオプティマイザ: 訓練の安定性を高めます。
3. ハイブリッドアテンションアーキテクチャによる効率化
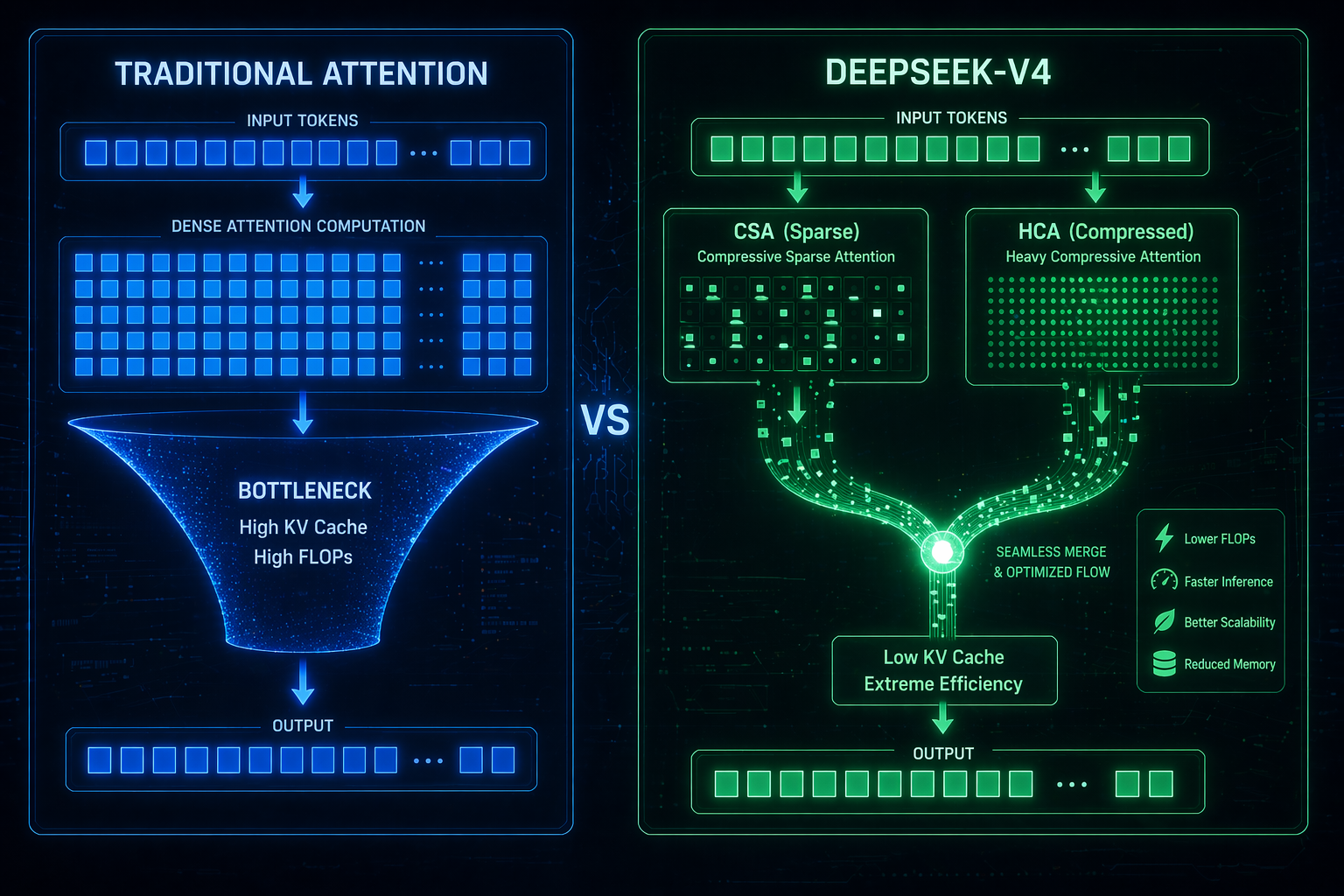
100万トークンコンテキスト の処理には膨大な計算能力が必要ですが、DeepSeek-V4 公式リリース は驚異的な最適化を示しています:
- ハイブリッドアテンションアーキテクチャ を搭載したV4-Proは、V3.2と比較してシングル推論FLOPsの27%しか必要としません。
- 同じ 100万トークンコンテキスト 設定下で、KVキャッシュの要件はV3.2のわずか10%です。
- 軽量なV4-Flashも ハイブリッドアテンションアーキテクチャ を利用して効率を極限まで高めています。
4. ベンチマーク:オープンモデルの新しいSOTA
DeepSeek-V4 公式リリース は最大32Tトークンで事前学習され、この オープンモデルの新しいSOTA を確保しました。
- DeepSeek-V4-Pro-Maxは オープンモデルの新しいSOTA を再定義し、先行モデルを圧倒します。
- 競技プログラミングにおいて、この オープンモデルの新しいSOTA はCodeforcesで23位にランクインしました。
- Putnam-2025において、DeepSeek-V4 公式リリース は120/120の完璧な証明スコアを達成しました。
5. エージェントAI向けのツールアップグレード

100万トークンコンテキスト を超えて、DeepSeek-V4 公式リリース はエージェントワークフローにおける オープンモデルの新しいSOTA としての地位を固めるためにツール呼び出しをアップグレードしました。
結論
DeepSeek-V4 公式リリース は単なるパラメータのアップグレードではありません。画期的な ハイブリッドアテンションアーキテクチャ を実装することで、100万トークンコンテキスト を高効率な現実に変えました。私たちは、次の時代を定義する オープンモデルの新しいSOTA を目撃しています。