DeepSeek-V4 Official Release: Million-Token Context, Hybrid Attention, and a New SOTA for Open Models

Today marks the highly anticipated DeepSeek-V4 official release. With the DeepSeek-V4 official release, the team has delivered a monumental leap in AI capabilities, specifically by mastering the million-token context. By introducing a revolutionary hybrid attention architecture, this update establishes a definitive new SOTA for open models.
Through a profound reconstruction of its underlying systems, the DeepSeek-V4 official release successfully breaks the efficiency barrier of ultra-long processing. Here are the core highlights of how its hybrid attention architecture and million-token context redefine the new SOTA for open models.
1. The Core Model Matrix: Built for a Million-Token Context
The DeepSeek-V4 official release preview includes two powerful Mixture-of-Experts (MoE) language models, both natively supporting a million-token context:
- DeepSeek-V4-Pro: Features 1.6T (trillion) total parameters, with 49B activated per token, easily handling a million-token context.
- DeepSeek-V4-Flash: Features 284B total parameters, with 13B activated per token, making the million-token context highly accessible.
2. Breakthrough: The Hybrid Attention Architecture
To achieve extreme efficiency under a million-token context, the DeepSeek-V4 official release introduces three key innovations, led by its hybrid attention architecture:
- Hybrid Attention Architecture: This hybrid attention architecture combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), significantly boosting computational efficiency for long contexts.
- Manifold-Constrained Hyper-Connections (mHC): Enhances traditional residual connections alongside the hybrid attention architecture.
- Muon Optimizer: Introduced during training to achieve faster convergence and greater training stability.
3. Efficiency Powered by the Hybrid Attention Architecture
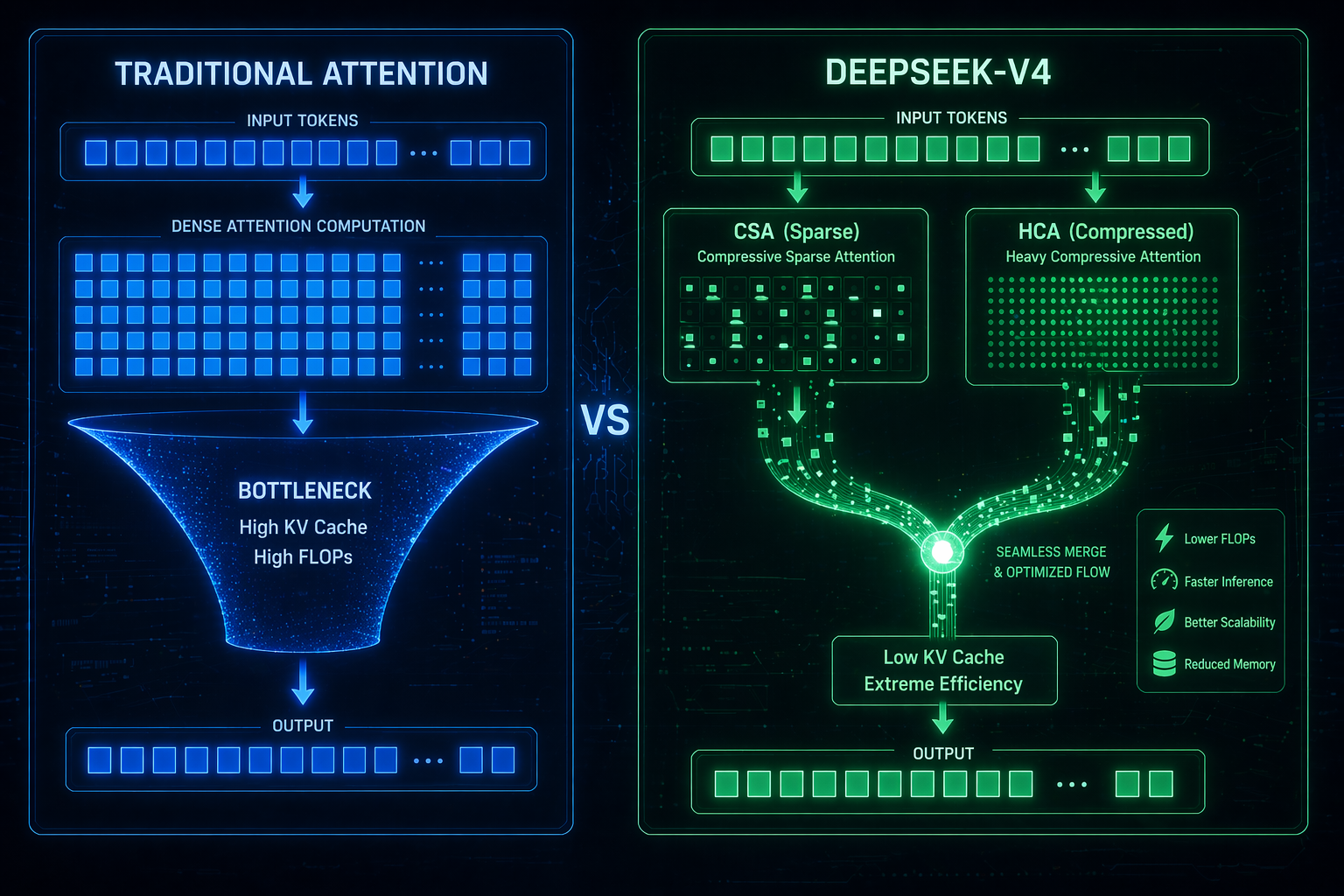
Processing a million-token context requires immense power, but the DeepSeek-V4 official release demonstrates an incredible squeeze on compute and memory:
- Powered by the hybrid attention architecture, DeepSeek-V4-Pro requires only 27% of the single-token inference FLOPs compared to V3.2.
- Under the same million-token context setting, its KV Cache requirement is a mere 10% of V3.2's.
- The lighter DeepSeek-V4-Flash utilizes the hybrid attention architecture to push efficiency even further.
4. Benchmarks: A New SOTA for Open Models
The DeepSeek-V4 official release was pre-trained on up to 32T high-quality tokens. In the post-training phase, On-Policy Distillation (OPD) was utilized to secure this new SOTA for open models.
- DeepSeek-V4-Pro-Max redefines the new SOTA for open models, comprehensively outperforming its predecessors in core tasks.
- In competitive programming, this new SOTA for open models ranks 23rd on the Codeforces human leaderboard.
- In the Putnam-2025 formal mathematical reasoning test, the DeepSeek-V4 official release achieved a perfect proof score of 120/120.
5. Tool Calling Upgrades Designed for Agentic AI

Beyond the million-token context, the DeepSeek-V4 official release upgrades its tool-calling mechanisms to solidify its position as the new SOTA for open models in Agent workflows:
- Introduced a new XML-format tool-calling schema (based on a special
<|DSML|>token), effectively mitigating escaping failures and reducing tool-call errors. - Adopted an