DeepSeek-V4 正式发布:百万 Token 上下文、混合注意力架构与开源模型新 SOTA
Fanch AIon 2 months ago

今天是备受瞩目的 DeepSeek-V4 正式发布之日。随着 DeepSeek-V4 正式发布,团队在 AI 能力上实现了历史性跨越,特别是完美驾驭了百万 Token 上下文。通过引入革命性的混合注意力架构,这次更新确立了绝对的开源模型新 SOTA。
通过对底层系统的深度重构,DeepSeek-V4 正式发布成功打破了超长处理的效率壁垒。以下是其混合注意力架构和百万 Token 上下文如何重新定义开源模型新 SOTA的核心亮点。
1. 核心模型矩阵:专为百万 Token 上下文打造
DeepSeek-V4 正式发布的预览版包含两款强大的混合专家 (MoE) 模型,原生支持百万 Token 上下文:
- DeepSeek-V4-Pro:1.6T 总参数,每 Token 激活 49B 参数,轻松应对百万 Token 上下文。
- DeepSeek-V4-Flash:284B 总参数,每 Token 激活 13B 参数,让百万 Token 上下文触手可及。
2. 突破:混合注意力架构
为了在百万 Token 上下文下实现极致效率,DeepSeek-V4 正式发布引入了三项关键创新,首当其冲的便是混合注意力架构:
- 混合注意力架构:该混合注意力架构结合了压缩稀疏注意力 (CSA) 与重度压缩注意力 (HCA),大幅提升计算效率。
- 流形约束超连接 (mHC):配合混合注意力架构增强传统残差连接。
- Muon 优化器:在训练中引入,实现更快收敛。
3. 混合注意力架构带来的效率飞跃
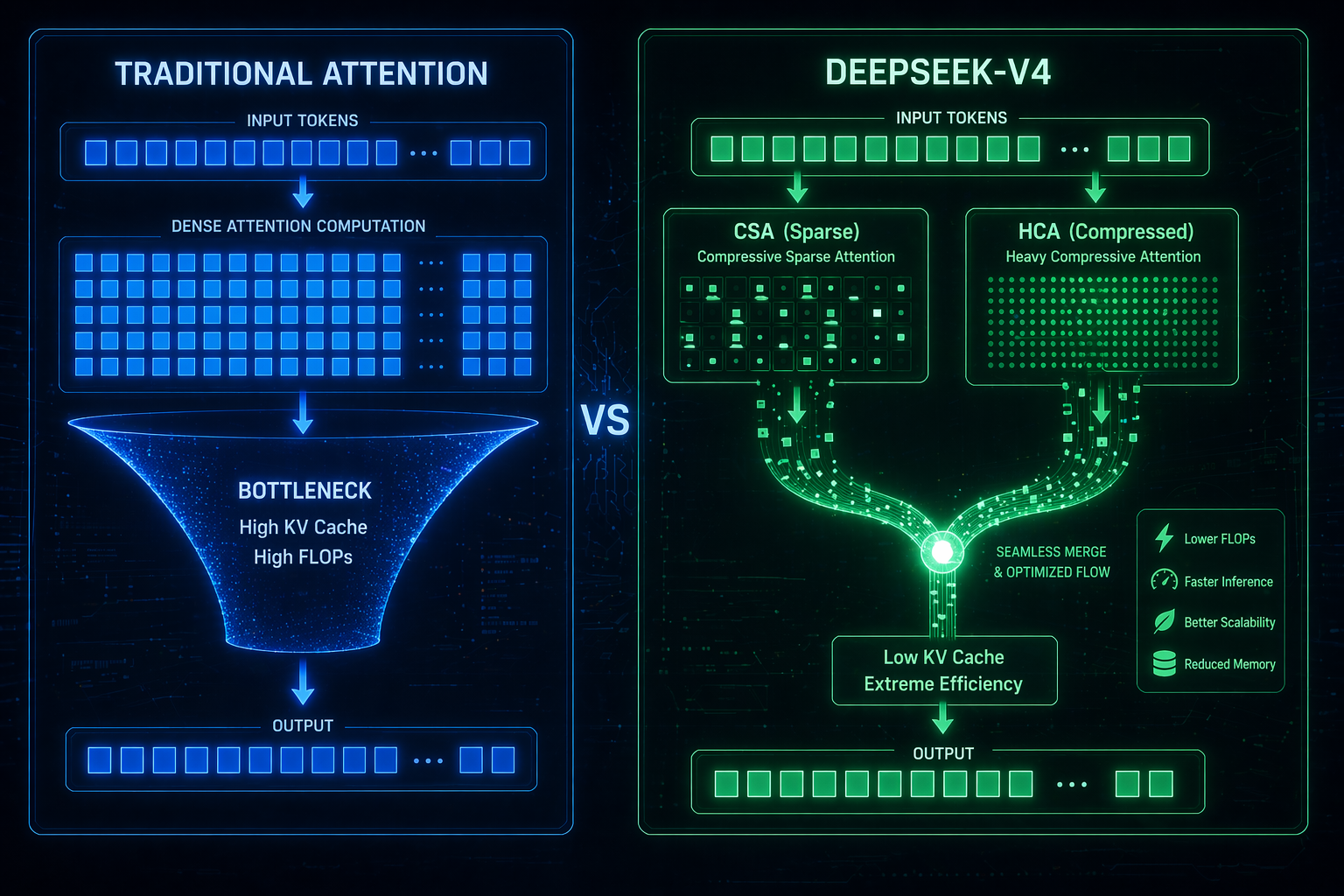
处理百万 Token 上下文需要巨大算力,但 DeepSeek-V4 正式发布展现了惊人的优化:
- 在混合注意力架构的加持下,DeepSeek-V4-Pro 的单 Token 推理 FLOPs 仅为 V3.2 的 27%。
- 在相同的百万 Token 上下文设置下,其 KV Cache 仅为 V3.2 的 10%。
- 更轻量的 DeepSeek-V4-Flash 同样利用混合注意力架构将效率推向极致。
4. 跑分:开源模型新 SOTA
DeepSeek-V4 正式发布在 32T 高质量 Token 上进行了预训练,并在后训练阶段利用同策略蒸馏锁定了这个开源模型新 SOTA。
- DeepSeek-V4-Pro-Max 重新定义了开源模型新 SOTA,在核心任务上全面超越前代。
- 在编程竞赛中,这个开源模型新 SOTA在 Codeforces 排名第 23。
- 在 Putnam-2025 测试中,DeepSeek-V4 正式发布取得了 120/120 的完美证明成绩。
5. 专为智能体打造的工具升级

除了百万 Token 上下文,DeepSeek-V4 正式发布还升级了工具调用,巩固了其作为 Agent 工作流开源模型新 SOTA的地位:
- 引入全新 XML 格式 Schema(基于
<|DSML|>),减少调用错误。 - 采用交叉思考机制,在多轮对话中保持连贯的思维链。
结语
DeepSeek-V4 正式发布不仅仅是参数升级。通过开创性的混合注意力架构,它将百万 Token 上下文变成了高效的现实。随着 V4 问世,我们见证了一个将定义超长文本处理时代的开源模型新 SOTA。